TiCDC Overview and Usage Scenarios
1. Why TiCDC exists
TiCDC is designed for incremental data replication out of TiDB.
Its two most common goals are:
- Disaster recovery and cross-system replication
- Data integration for analytics/search/recommendation pipelines
TiDB Binlog solved part of this problem space historically, but TiCDC improves key areas such as scalability, sink throughput, scheduling, and recovery behavior.
Typical improvements include:
- Better horizontal scaling by splitting replication workload
- Better sink throughput (for example, multi-partition Kafka consumption patterns)
- Better scheduling and self-healing under node movement or failure
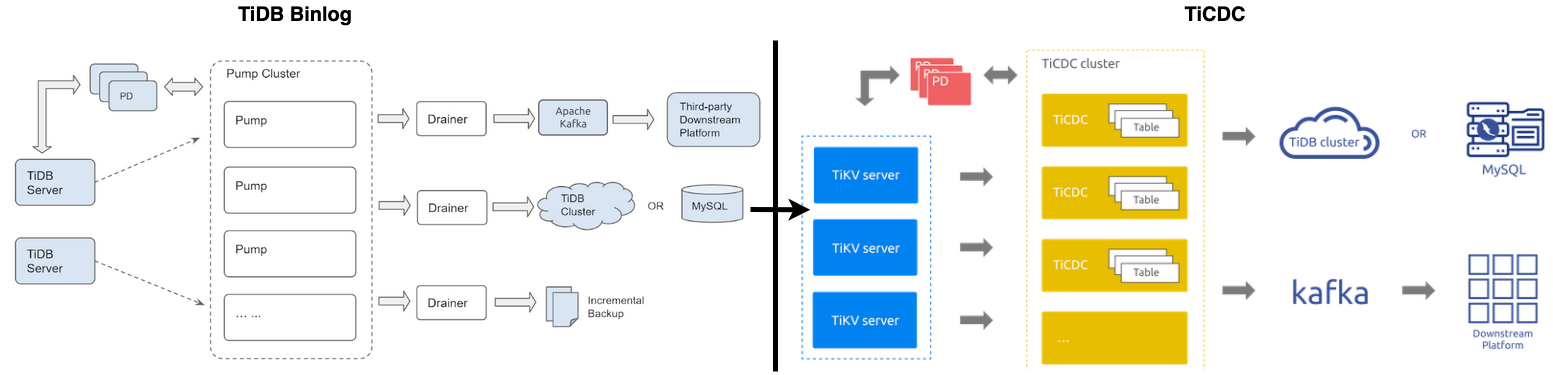
2. Position in the architecture
TiCDC sits between TiDB and downstream systems.
Typical upstream/downstream flow:
App -> TiDB -> TiCDC -> Kafka/MySQL/other consumers
It enables TiDB to become part of a larger data platform instead of staying isolated in one transactional path.
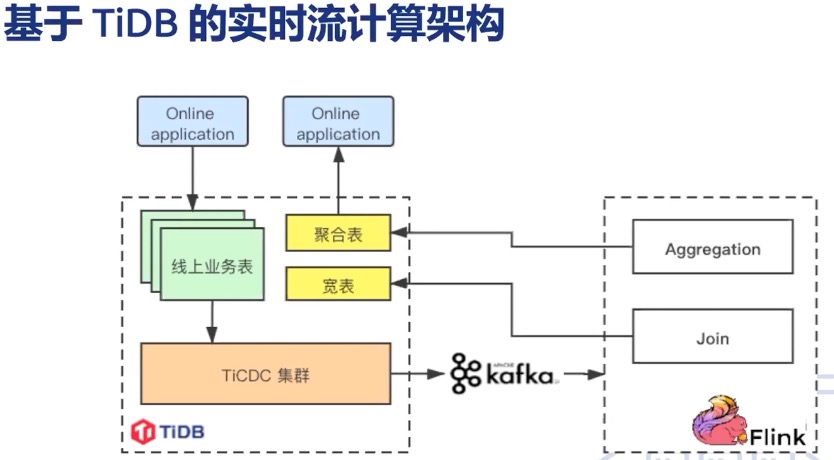
3. Typical production scenarios
3.1 Xiaohongshu
A common pattern is:
TiDB -> TiCDC -> Kafka -> Flink -> TiDB
This supports content-related processing, recommendation tagging, and growth-oriented analytics pipelines.
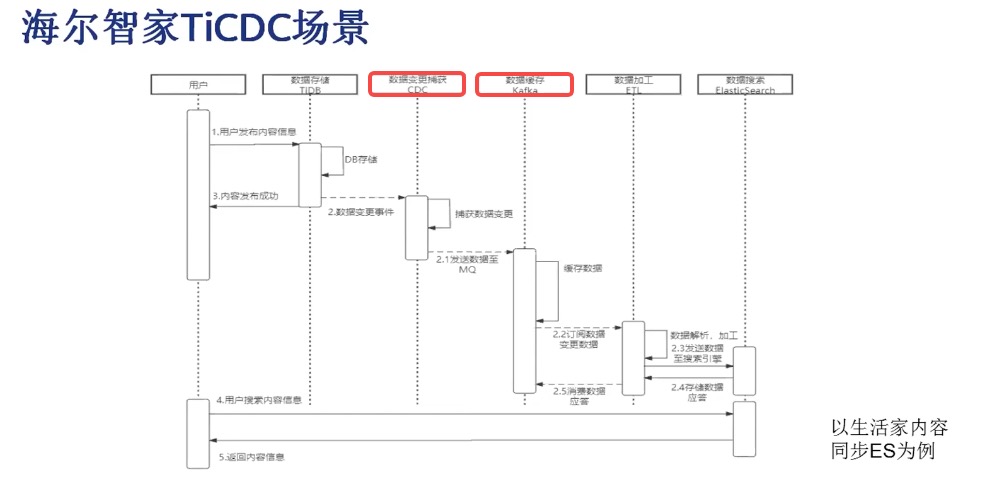
3.2 Haier Smart Home
A common pattern is:
TiDB -> TiCDC -> Kafka -> Elasticsearch
This supports near real-time indexing and search use cases.
3.3 360
Typical goals include:
- Incremental extraction
- Dual-cluster hot backup
- Stream processing integration
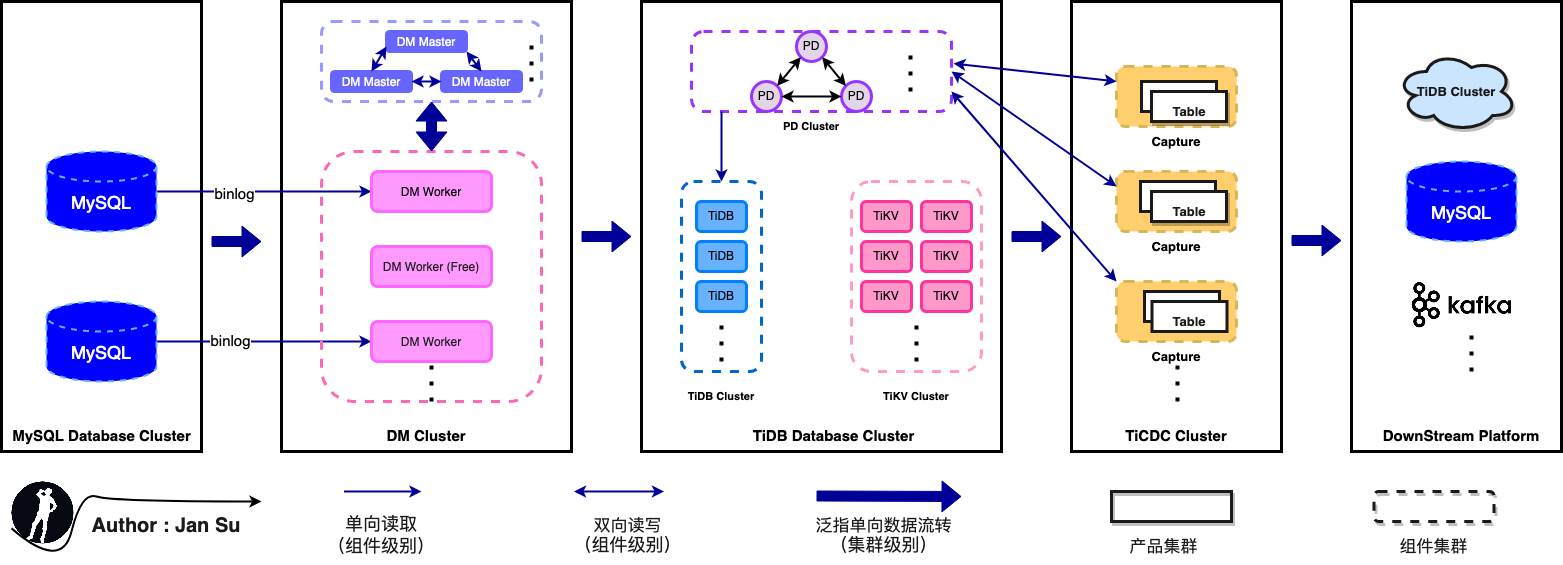
4. Quick start
4.1 Deploy TiCDC nodes with TiUP
tiup cluster display tidb-testIf TiCDC nodes are not present, add them through a scale-out file.
# scale-out-cdc.yaml
cdc_servers:
- host: 172.16.6.155
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300
- host: 172.16.6.196
gc-ttl: 86400
data_dir: /data/deploy/install/data/cdc-8300tiup cluster scale-out tidb-test scale-out-cdc.yaml4.2 Create a Kafka sink changefeed
tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="kafka://172.16.6.155:9092/tidb-test?protocol=canal-json&kafka-version=2.4.0&partition-num=2&max-message-bytes=67108864&replication-factor=1"Then consume from Kafka and validate DML/DDL events.
4.3 Create a MySQL sink changefeed
tiup cdc cli changefeed create --pd=http://172.16.6.155:2379 \
--sink-uri="mysql://jan:123123@172.16.6.155:3306/?time-zone=&worker-count=16&max-txn-row=5000" \
--changefeed-id="simple-replication-task" \
--sort-engine="unified" \
--config=changefeed.toml5. Operational checkpoints
When troubleshooting TiCDC in production, prioritize:
- Checkpoint lag and resolved-ts progression
- Sink throughput and backpressure behavior
- Capture scheduling balance and rebalance frequency
- Error events in changefeed state and sink logs