TiDB Lightning Architecture
0. Quick Index
- Source location:
tidb/br/cmd/tidb-lightning - Main flow:
run -> preCheck -> checkpoint -> restoreTables -> clean - Most critical stage:
restoreTables - Two high-impact concurrency knobs:
table-concurrency,index-concurrency
1. Positioning and Architecture View
TiDB Lightning is the bulk-ingest component, and its current code lives in the TiDB repository.
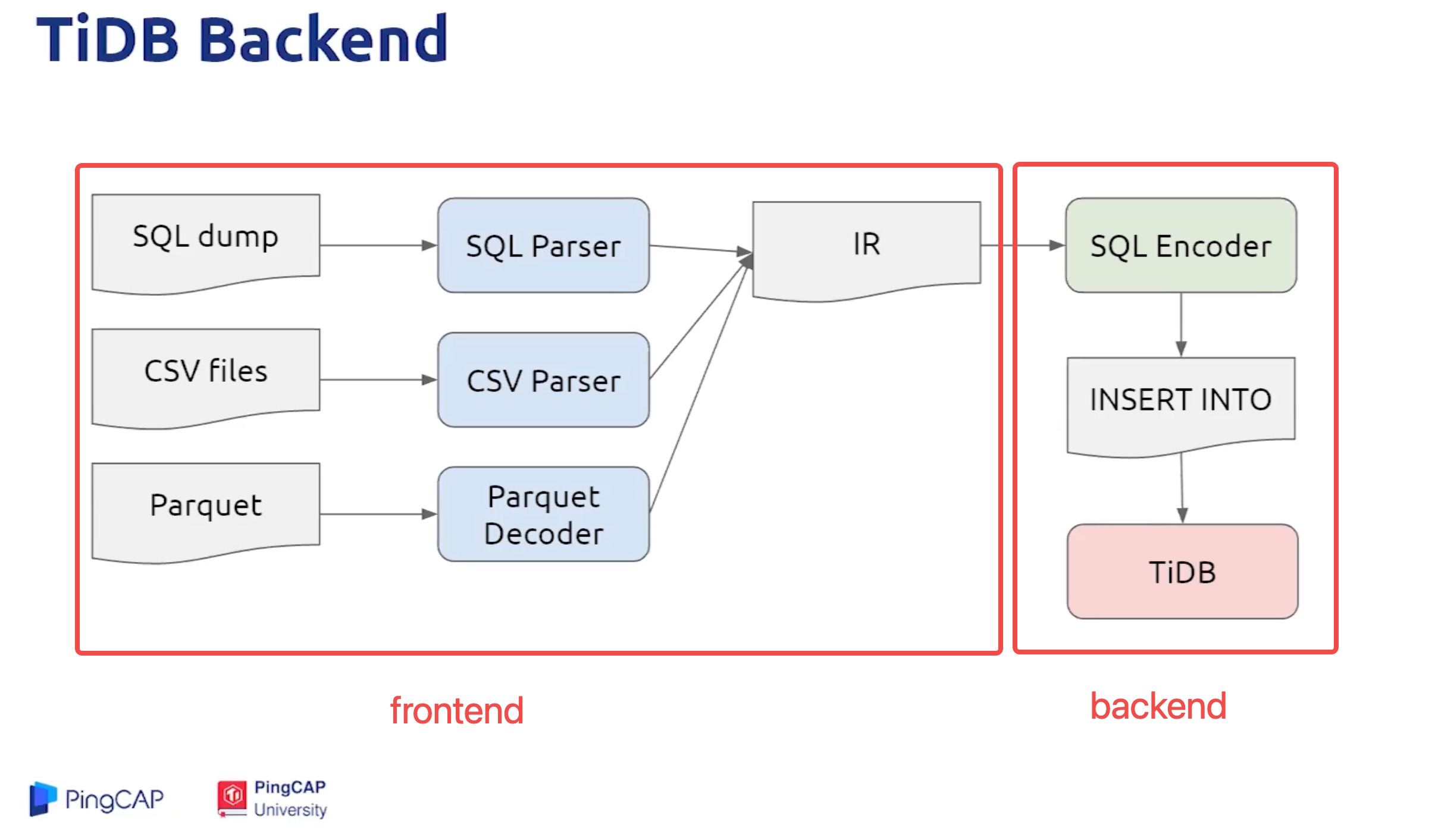
A practical way to read the architecture is to split it into two layers:
- Frontend: parse source files and encode them into KV
- Backend: write KV to downstream and control import stages
2. Startup Chain
Use this chain to quickly navigate code entry points:
main()
-> app.RunOnceWithOptions
-> lightning.run
-> restore.NewRestoreController
-> Controller.runInside Controller.run, key steps are executed in order:
setGlobalVariablesrestoreSchemapreCheckRequirementsinitCheckpointrestoreTablesfullCompact(historical stage)cleanCheckpoints
3. Key Stages
3.1 preCheckRequirements
Purpose: validate environment and dependencies before import starts, so failures are caught early.
3.2 initCheckpoint
Purpose: initialize or recover checkpoint state for resume/retry behavior.
Start with this interface:
3.3 restoreTables (core)
restoreTables is the center of throughput and stability. It includes:
- parallel execution of table and index tasks
- cluster-level controls around import stages
- chunk splitting, task dispatch, and post-process (checksum/analyze/rebase)
Common concurrency knobs:
table-concurrency: table-data import concurrencyindex-concurrency: index import concurrency
Common extra operations in local backend mode:
- temporary adjustment of specific PD schedulers
- GC control when required
- checksum handler initialization
Two key functions for chunk behavior:
3.4 fullCompact (historical stage)
fullCompact was mainly used as an additional compaction step in earlier ingestion models. In current practice, it is usually not the primary optimization path.
Historical reference:
4. Frontend and Backend
4.1 Frontend (parse/encode)
Responsibility: parse CSV/SQL/Parquet source data and encode them into KV.
Relevant entry points:
4.2 Backend (write/import)
Responsibility: execute downstream writes, import scheduling, and stage control.
Backend mode (tidb/local) affects:
- write path into TiKV
- cluster control strategy during import
- throughput and resource profile
5. Suggested Parameter Reading Order
If your goal is performance troubleshooting, start with:
table-concurrencyindex-concurrency- chunk sizing and source-file splitting strategy
- backend mode selection (tidb/local)
6. Troubleshooting Checkpoints
- whether checkpoint keeps moving forward
- whether oversized tables/files cause poor concurrency balance
- whether downstream write path becomes the bottleneck
- whether post-process (checksum/analyze) dominates tail latency