DM
TiDB DM: Architecture, Components, and Operations Overview
Integrated from DM docs: architecture, quick start, Master/Worker/Syncer, shard DDL, metrics, and troubleshooting.
DM (TiDB Data Migration) is used to continuously migrate MySQL (single instance or sharded cluster) into TiDB.
0. Quick Index
0.1 What DM Solves
- Full migration:
dump + load - Incremental replication:
binlog -> TiDB - Shard merge: multiple upstream tables merged into one downstream table
0.2 When to Prefer DM
- You need MySQL-to-TiDB migration with a short downtime window
- You need full load first, then incremental catch-up before cutover
- Upstream is sharded MySQL and requires routing/merge
0.3 Common Non-DM Scenario
- TiDB changefeed to downstream systems (this is usually TiCDC)
1. Architecture and Data Flow
Integrated architecture diagram (from DM docs):
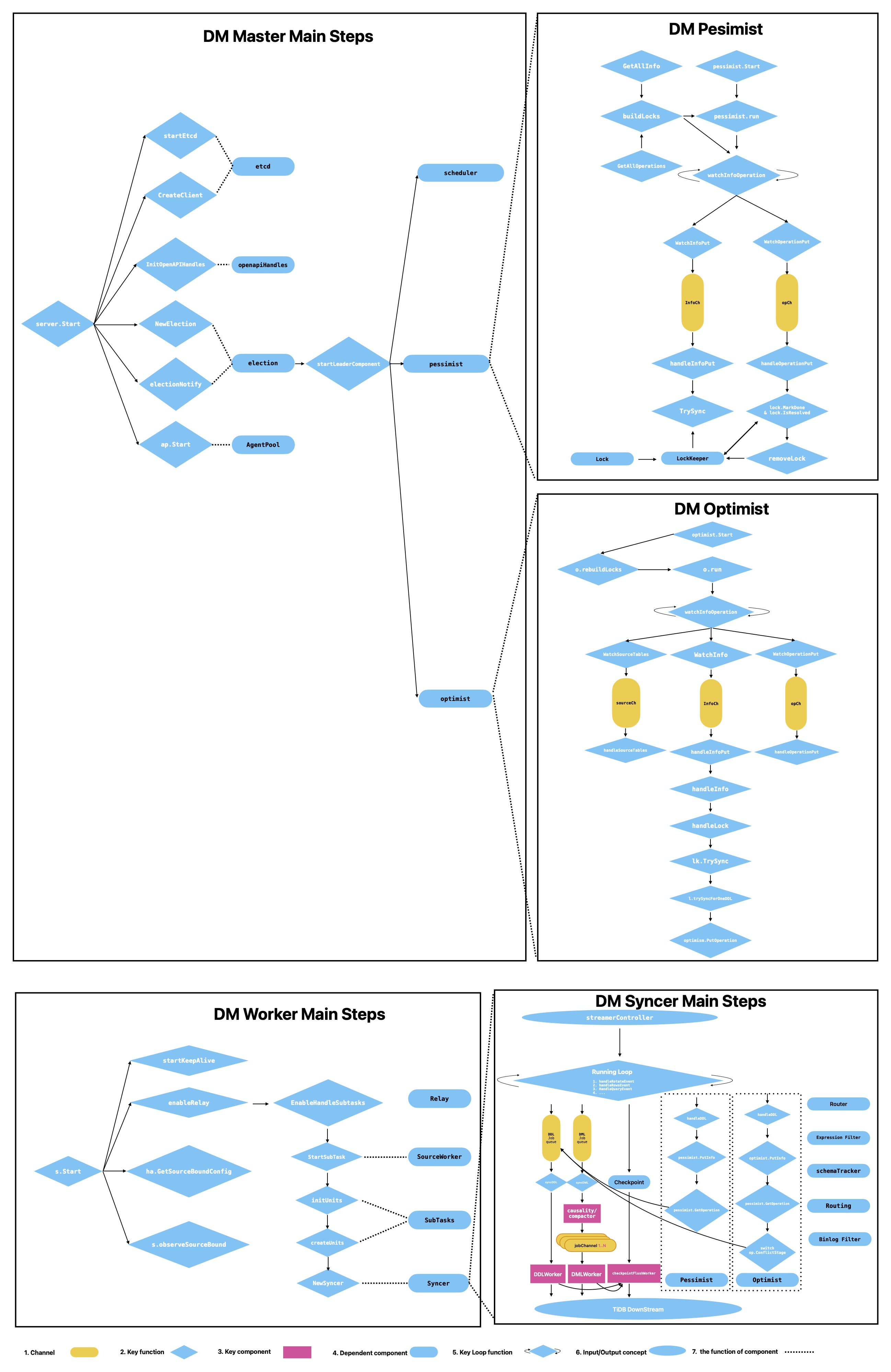
1.1 Key Object Relationships
1 source ~= 1 subtask- A
subtaskruns on adm-worker dm-masterhandles control plane (scheduling, election, coordination)etcdhandles metadata persistence and state sync
1.2 Main Data Flow
- Dumper exports upstream snapshot
- Loader imports into TiDB
- Syncer continuously consumes binlog and applies DML/DDL
If relay is enabled, the flow becomes:
Upstream MySQL -> Relay Log (local on worker) -> Syncer -> TiDB
2. Quick Start (Condensed)
2.1 Preconditions
- binlog is enabled on upstream MySQL
- binlog retention covers the catch-up window
- account privileges and network connectivity are confirmed
2.2 Deployment Example (TiUP)
tiup install dm
tiup dm deploy dm-test v2.0.1 /home/tidb/dm/topology.yaml --user root -p
tiup dm start dm-test
tiup dm display dm-test2.3 Example Upstream Data
create database user;
create database store;
create database log;
use user;
create table information (id int primary key,name varchar(20));
create table log (id int primary key,name varchar(20));
use log;
create table messages(id int primary key,name varchar(20));3. DM Master (Control Plane)
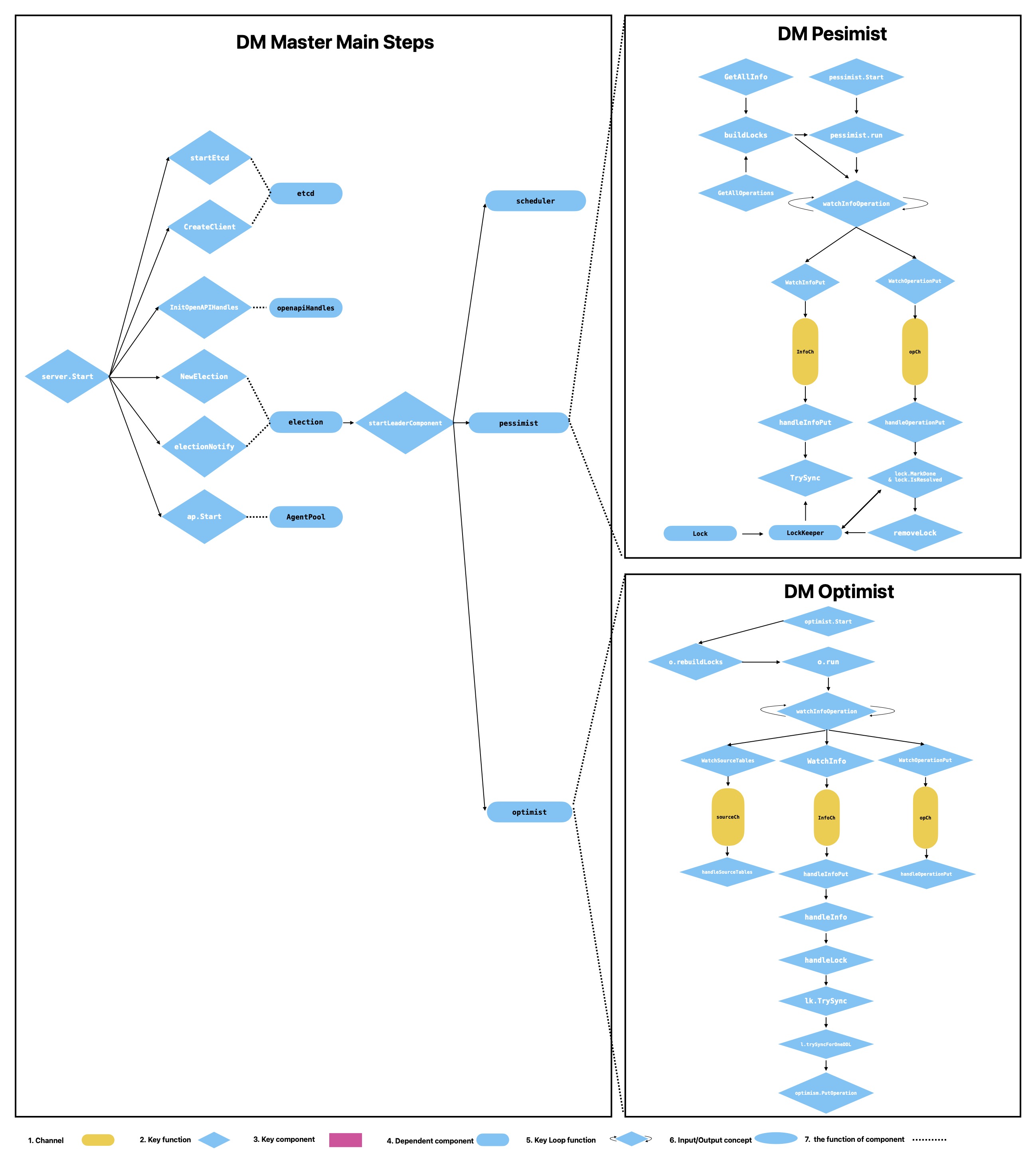
3.1 Etcd and High Availability
- Master critical states are persisted in etcd
- With election, only the leader executes key control logic
3.2 OpenAPI / dmctl
- OpenAPI and dmctl are both operational entry points
- Requests are handled by the leader; non-leaders forward them
3.3 Election
campaignLoopdrives continuous leader election- The leader starts key components:
Scheduler,Pessimist,Optimist
3.4 Scheduler
Scheduler handles:
- worker registration/offline handling
- keepalive state observation
- source add/remove event watching
- subtask scheduling and migration
4. DM Worker (Data Plane)
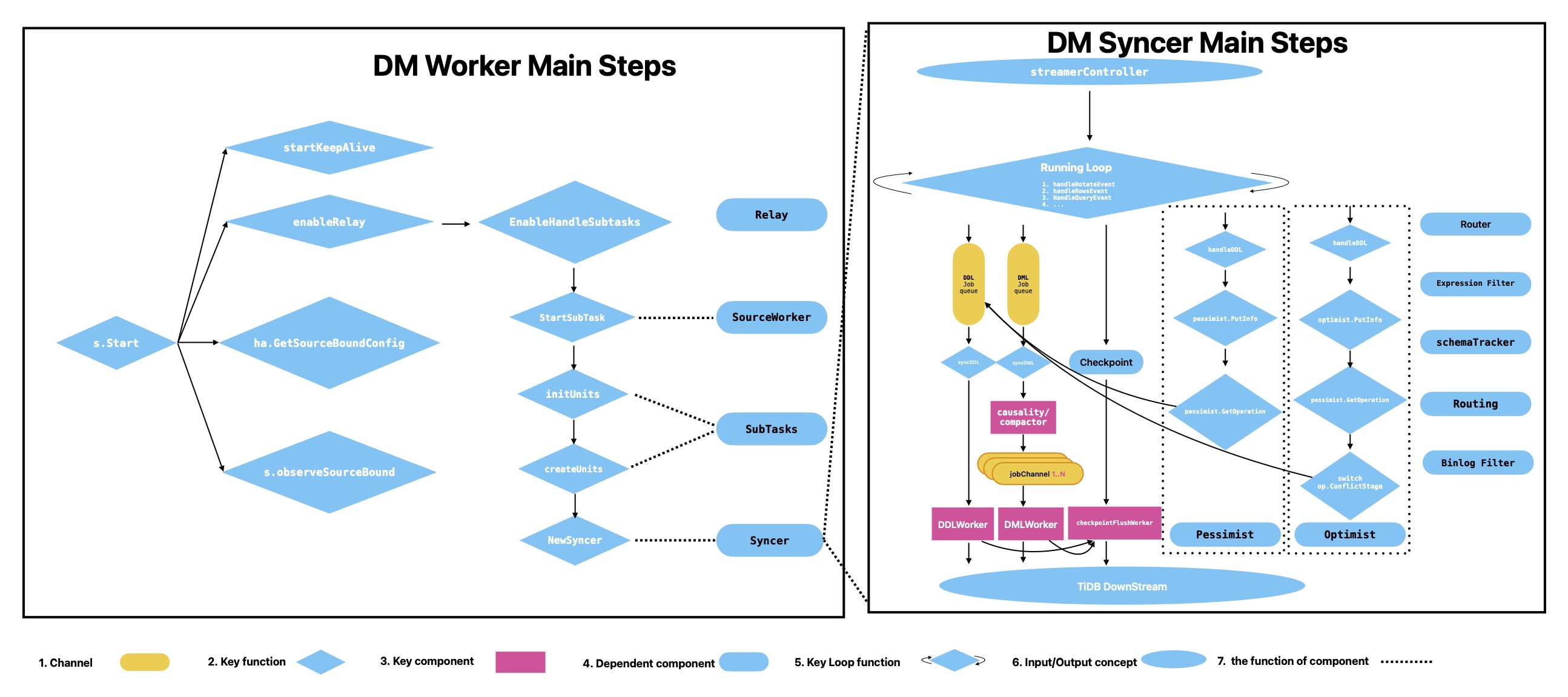
Typical components after worker startup:
- KeepAlive
- RelayHandler (optional)
- SubTasks
- Syncer
4.1 KeepAlive
- Uses etcd lease/TTL heartbeat to maintain liveness
- Default TTL is 1 minute
- Master can reschedule if a worker becomes unhealthy
4.2 Relay
- When enabled, binlog is first written to local relay, then consumed by syncer
- Improves stability when upstream binlog reading is unstable
Typical directory:
<deploy_dir>/relay_log/
|-- <server-uuid>.000001/
| |-- mysql-bin.000001
| `-- relay.meta
`-- server-uuid.index4.3 SubTask and SourceWorker
- SubTask is the execution unit after task splitting
- SourceWorker manages subtask/state/relay lifecycle for one source
5. Syncer (Incremental Replication Engine)
5.1 StreamController
Handles binlog stream control:
- creates stream from remote or relay
- resets by position or GTID
- continuously reads next event
5.2 Main Loop
The Syncer main loop dispatches events to branches:
- rotate event
- query event (DDL)
- rows event (DML)
Key rows events include:
WRITE_ROWS_EVENTUPDATE_ROWS_EVENTDELETE_ROWS_EVENT
5.3 syncDML
syncDML dispatches jobs from dmlJobCh to:
- Compactor (optional)
- Causality
- DML worker queues
Common tuning knobs:
worker-count(parallelism)batch(batch size)
5.4 Causality
- buckets conflicts by PK/UK
- keeps conflicting events ordered
- executes non-conflicting events in parallel
5.5 syncDDL / DDLWorker / checkpointWorker
syncDDLswitches logic by shard mode (pessimist/optimist)DDLWorkerhandles DDL split/filter/execute and metricscheckpointWorkerflushes progress for resumability and final consistency
6. Shard DDL: Pessimist vs Optimist
| Dimension | Pessimist Mode | Optimist Mode |
|---|---|---|
| DML impact | Related DML may be blocked | Tries to keep main DML path unblocked |
| Coordination | Owner executes downstream DDL once | Schema-state conflict detection and coordination |
| Key structures | Info / Operation / Lock | Info / Operation (with more schema context) |
| Typical issue | lock not resolved for long time | schema conflict resolution failure |
7. Metrics and Monitoring
7.1 High-Priority Metrics
replicate lagremaining time to syncshard lock resolvingDML queue remain length- relay disk capacity and remaining space
7.2 Two Core Formulas
remainingSeconds = remainingSize / bytesPerSec
bytesPerSec = (totalBinlogSize - lastBinlogSize) / secondslag = now - tsOffset - headerTS8. Troubleshooting Runbook (Suggested Order)
- First decide whether the issue is in control plane or data plane
- If lag grows, check downstream write capacity, then relay IO, then syncer parallel settings
- If stuck on DDL, check
shard lock resolvingand routing consistency - Use dmctl/OpenAPI for manual intervention only when needed
9. Etcd Key Observability
10. References
- DM architecture: https://docs.pingcap.com/tidb/stable/dm-arch
- DM OpenAPI: https://docs.pingcap.com/tidb/stable/dm-open-api
- Shard merge (pessimistic): https://docs.pingcap.com/tidb-data-migration/v5.3/feature-shard-merge-pessimistic
- Shard merge (optimistic): https://docs.pingcap.com/tidb-data-migration/v5.3/feature-shard-merge-optimistic
- tiflow DM source tree: https://github.com/pingcap/tiflow/tree/master/dm