Lightning
TiDB Lightning 架构
0. 快速索引
- 代码位置:
tidb/br/cmd/tidb-lightning - 主流程:
run -> preCheck -> checkpoint -> restoreTables -> clean - 最关键阶段:
restoreTables - 两个高频并发参数:
table-concurrency、index-concurrency
1. 定位与整体视角
TiDB Lightning 是面向大规模导入的工具链组件,当前代码在 TiDB 仓库中。
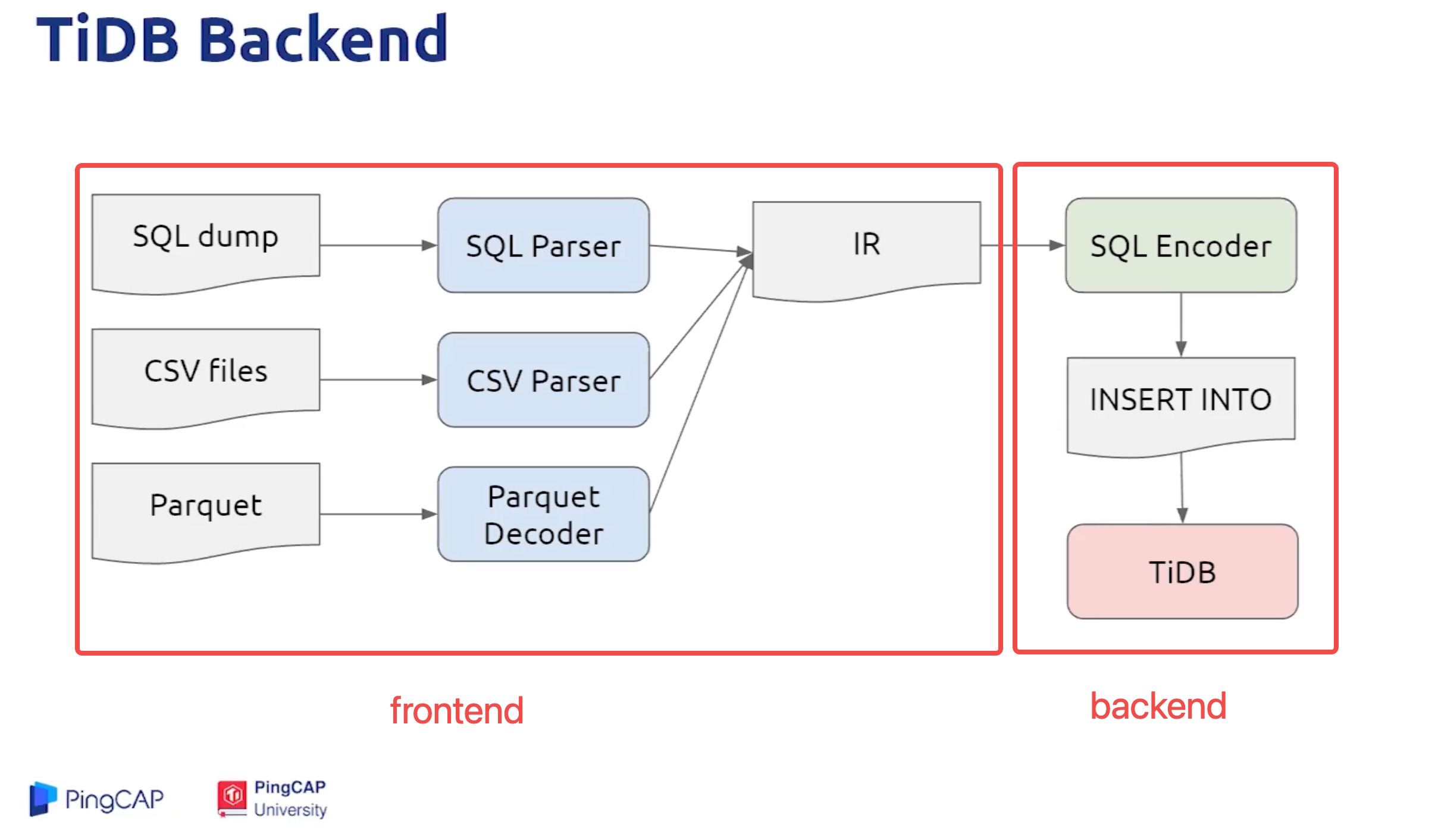
从架构上看,可以先按两层理解:
- Frontend:读取源文件并编码为 KV
- Backend:将 KV 写入下游并完成导入阶段控制
2. 启动链路
可以按下面这条链路快速定位入口:
main()
-> app.RunOnceWithOptions
-> lightning.run
-> restore.NewRestoreController
-> Controller.runController.run 内部会按顺序执行关键步骤:
setGlobalVariablesrestoreSchemapreCheckRequirementsinitCheckpointrestoreTablesfullCompact(历史阶段)cleanCheckpoints
3. 关键阶段
3.1 preCheckRequirements
职责:在导入前检查环境与依赖是否满足,避免任务启动后才暴露基础问题。
3.2 initCheckpoint
职责:初始化/恢复 checkpoint 状态,支持断点恢复与失败重试。
建议先看 checkpoint 接口:
3.3 restoreTables(核心)
restoreTables 是导入吞吐和稳定性的核心阶段,包含:
- 表任务与索引任务并发执行
- 导入前后的一些集群控制动作
- chunk 切分、任务分发、后处理(checksum/analyze/rebase)
常见并发参数:
table-concurrency:表数据导入并发index-concurrency:索引导入并发
在 local backend 下常见额外动作:
- 暂时调整部分 PD 调度行为
- 在必要场景下控制 GC
- 初始化 checksum handler
和切分相关的两个关键函数:
3.4 fullCompact(历史阶段)
fullCompact 主要用于早期导入模型中的压实补充步骤;在新版本实践中通常不作为主要优化手段。
参考历史变更:
4. Frontend 与 Backend
4.1 Frontend(解析/编码)
职责:把 CSV/SQL/Parquet 等源数据解析并编码为 KV。
相关入口:
4.2 Backend(写入/导入)
职责:执行下游写入、导入调度与阶段控制。
不同 backend(tidb/local)会影响:
- 数据写入路径
- 导入阶段的集群控制策略
- 吞吐/资源使用特征
5. 参数阅读顺序(建议)
如果你在做性能排查,建议优先看:
table-concurrencyindex-concurrency- chunk 大小与源文件切分策略
- backend 模式选择(tidb/local)
6. 排障观察点
- checkpoint 是否持续推进
- 单表/单文件是否过大导致并发不均衡
- 导入阶段是否触发下游写入瓶颈
- 后处理(checksum/analyze)是否成为尾部耗时