DM
DM 架构与组件总览
整合自 DM 系列文档:架构、快速上手、Master/Worker/Syncer、分片 DDL、指标与排障。
DM(TiDB Data Migration)用于将 MySQL(单实例或分片集群)持续迁移到 TiDB。
0. 快速索引
0.1 DM 解决什么问题
- 全量迁移:
dump + load - 增量复制:
binlog -> TiDB - 分库分表合并:多个上游表合并到一个下游表
0.2 什么时候优先用 DM
- 需要从 MySQL 迁移到 TiDB,并尽量缩短停机窗口
- 需要先全量,再增量追平后切换
- 上游是分片 MySQL,需要做路由与表合并
0.3 常见非 DM 场景
- TiDB 变更订阅到下游系统(这通常是 TiCDC 场景)
1. 架构与数据流
整合架构图(来自 DM 系列文档):
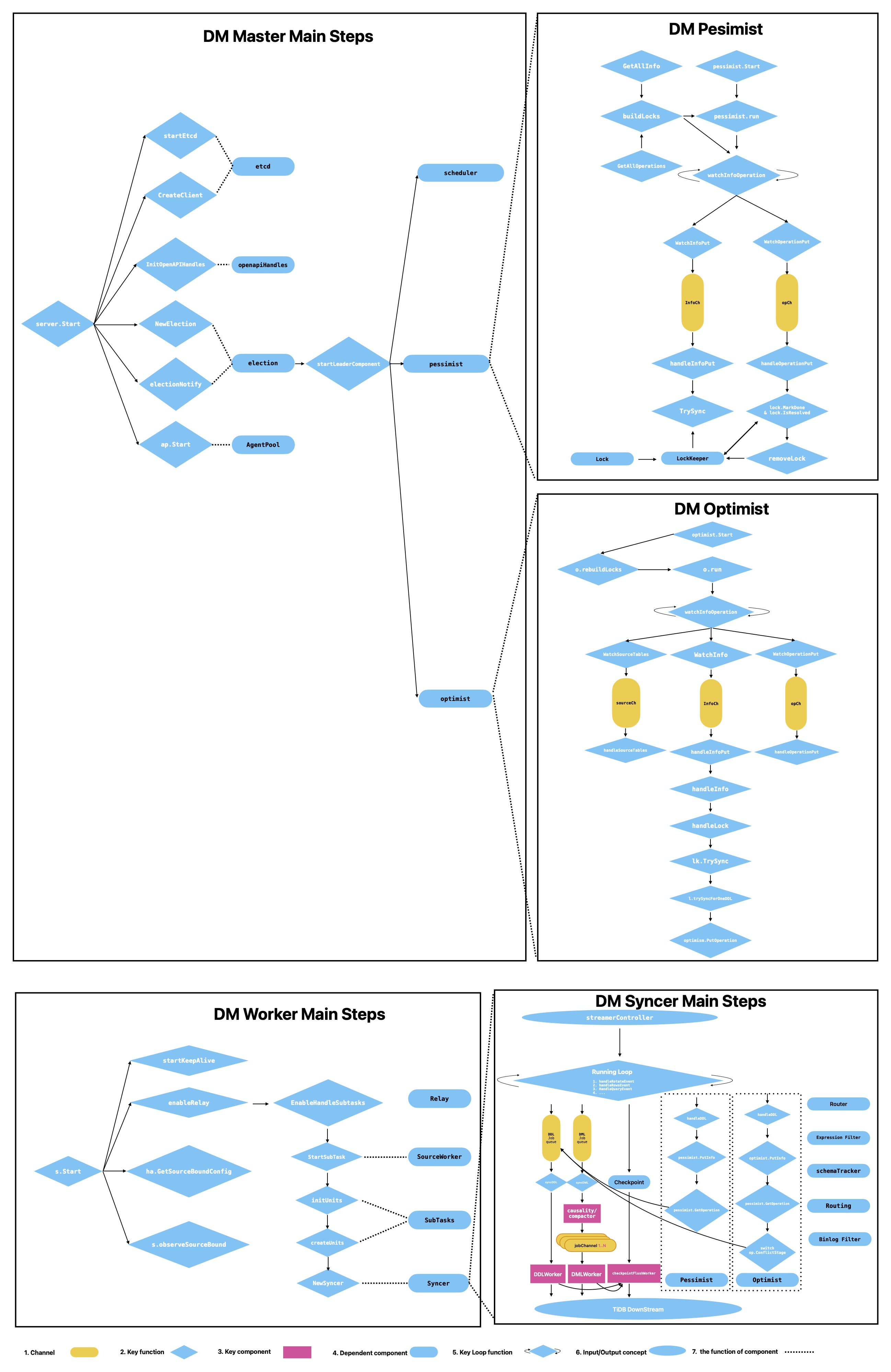
1.1 关键对象关系
1 source ~= 1 subtasksubtask运行在某个dm-workerdm-master负责控制面(调度、选主、协调)etcd负责元信息持久化与状态同步
1.2 数据流主线
- Dumper 导出上游快照
- Loader 导入 TiDB
- Syncer 持续消费 binlog 并应用 DML/DDL
如果启用 relay,链路会变成:
Upstream MySQL -> Relay Log (worker 本地) -> Syncer -> TiDB
2. 快速上手(精简版)
2.1 前置条件
- 上游 MySQL 已启用 binlog
- binlog 保留策略满足追平窗口
- 账号权限与网络连通性已确认
2.2 部署示例(TiUP)
tiup install dm
tiup dm deploy dm-test v2.0.1 /home/tidb/dm/topology.yaml --user root -p
tiup dm start dm-test
tiup dm display dm-test2.3 上游示例数据
create database user;
create database store;
create database log;
use user;
create table information (id int primary key,name varchar(20));
create table log (id int primary key,name varchar(20));
use log;
create table messages(id int primary key,name varchar(20));3. DM Master(控制面)
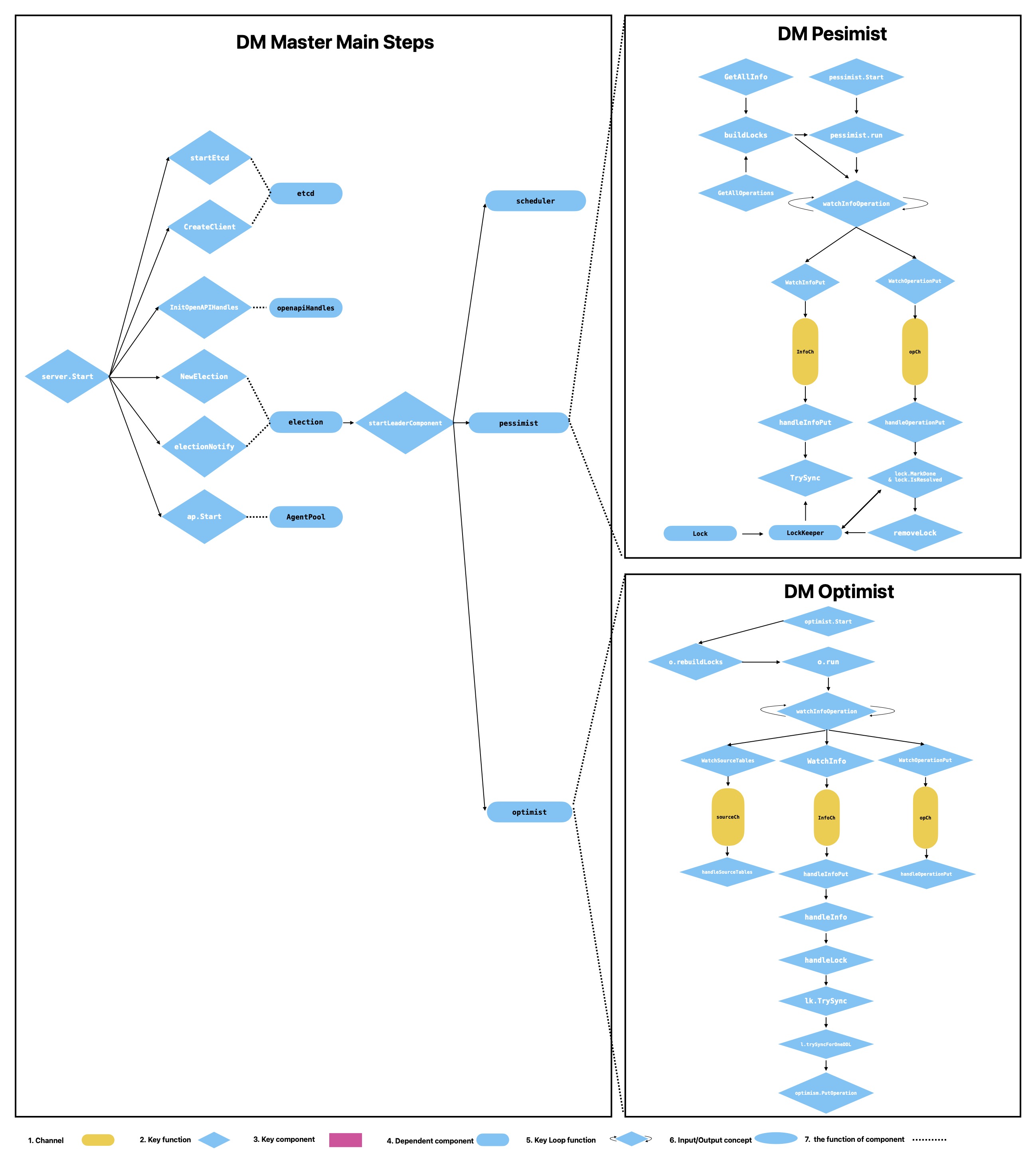
3.1 Etcd 与高可用
- Master 的关键状态持久化在 etcd
- 通过选主机制,只有 leader 执行关键控制逻辑
3.2 OpenAPI / dmctl
- OpenAPI 与 dmctl 都是运维入口
- 请求由 leader 处理,非 leader 负责转发
3.3 Election
campaignLoop负责持续选主- leader 拉起关键组件:
Scheduler、Pessimist、Optimist
3.4 Scheduler
Scheduler 负责:
- worker 注册/下线处理
- keepalive 状态观察
- source 配置增删监听
- subtask 调度与迁移
4. DM Worker(数据面)
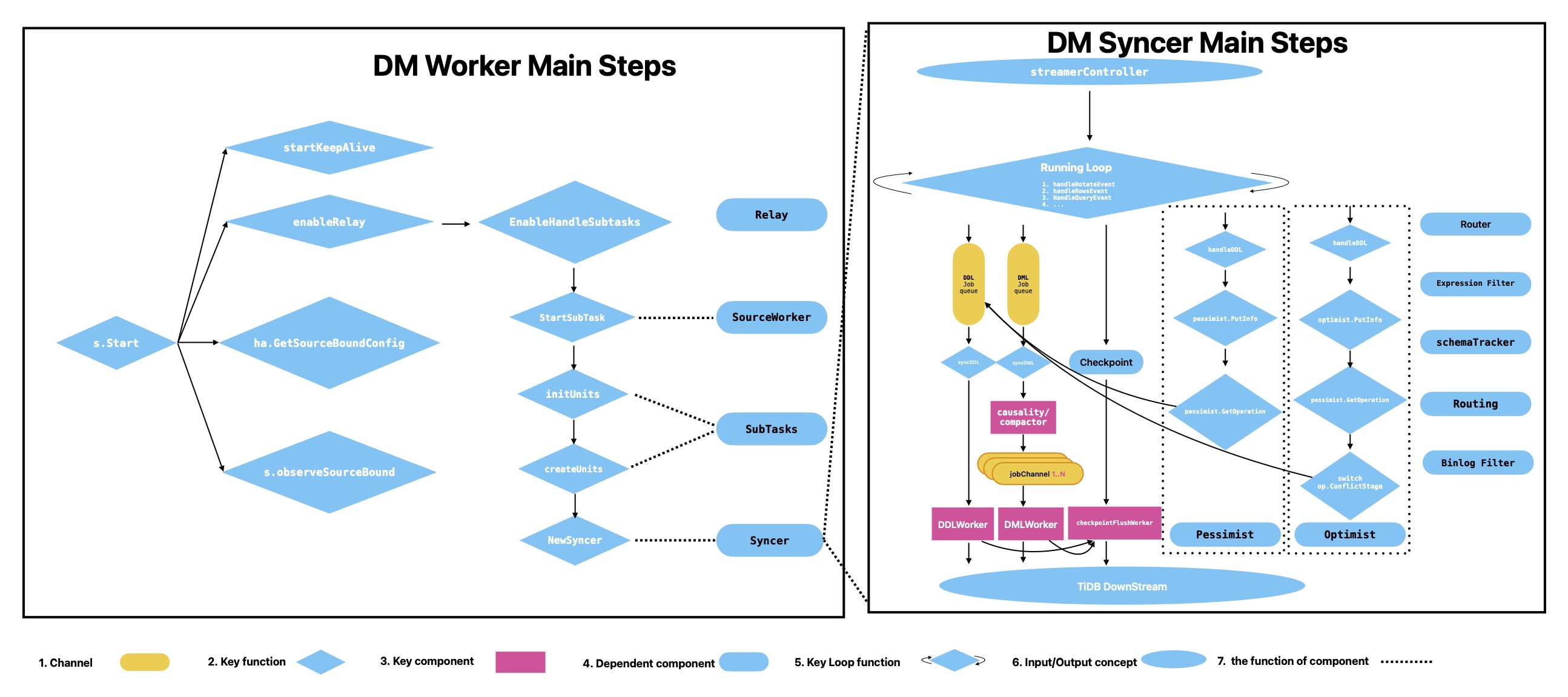
Worker 启动后常见组件:
- KeepAlive
- RelayHandler(可选)
- SubTasks
- Syncer
4.1 KeepAlive
- 通过 etcd lease/TTL 心跳维持在线状态
- 默认 TTL 为 1 分钟
- worker 异常时,Master 可触发重调度
4.2 Relay
- 启用后先落本地 relay,再由 syncer 消费
- 作用是降低上游 binlog 抖动对复制稳定性的影响
典型目录:
<deploy_dir>/relay_log/
|-- <server-uuid>.000001/
| |-- mysql-bin.000001
| `-- relay.meta
`-- server-uuid.index4.3 SubTask 与 SourceWorker
- SubTask 是任务拆分后的执行单元
- SourceWorker 负责单个 source 的子任务、状态与 relay 生命周期
5. Syncer(增量复制引擎)
5.1 StreamController
负责 binlog 读取控制:
- 从远端或 relay 生成事件流
- 按位点或 GTID 重置
- 连续读取下一条事件
5.2 主循环
Syncer 主循环会分发事件到不同处理分支:
- rotate event
- query event(DDL)
- rows event(DML)
rows event 重点包括:
WRITE_ROWS_EVENTUPDATE_ROWS_EVENTDELETE_ROWS_EVENT
5.3 syncDML
syncDML 会把作业从 dmlJobCh 分发到:
- Compactor(可选)
- Causality
- DML worker queues
常见调优项:
worker-count(并行度)batch(批量规模)
5.4 Causality
- 通过 PK/UK 做冲突分桶
- 冲突事件保持有序
- 无冲突事件并行执行
5.5 syncDDL / DDLWorker / checkpointWorker
syncDDL根据 shard mode 切换悲观/乐观逻辑DDLWorker负责 DDL 拆分、过滤、执行与指标记录checkpointWorker负责断点刷新,保障可恢复与最终一致性
6. 分片 DDL:悲观 vs 乐观
| 维度 | 悲观模式(Pessimist) | 乐观模式(Optimist) |
|---|---|---|
| DML 影响 | 可能阻塞相关 DML | 尽量不阻塞主 DML 路径 |
| 协调方式 | owner 执行一次下游 DDL | 基于 schema 状态做冲突检测与协调 |
| 关键结构 | Info / Operation / Lock | Info / Operation(含更多 schema 上下文) |
| 典型问题 | lock 长时间未 resolved | schema 冲突判定失败 |
7. 指标与监控
7.1 高优先级指标
replicate lagremaining time to syncshard lock resolvingDML queue remain length- relay 磁盘容量与剩余空间
7.2 两个核心公式
remainingSeconds = remainingSize / bytesPerSec
bytesPerSec = (totalBinlogSize - lastBinlogSize) / secondslag = now - tsOffset - headerTS8. 排障 Runbook(建议顺序)
- 先判断问题在控制面还是数据面
- 如果 lag 上升,先看下游写入能力,再看 relay IO,再看 syncer 并行参数
- 如果卡在 DDL,先看
shard lock resolving与路由规则一致性 - 必要时再用 dmctl/OpenAPI 做人工干预
9. Etcd Key 观察点
10. 参考
- DM 架构:https://docs.pingcap.com/zh/tidb/stable/dm-arch
- DM OpenAPI:https://docs.pingcap.com/tidb/stable/dm-open-api
- Shard Merge(悲观):https://docs.pingcap.com/zh/tidb-data-migration/v5.3/feature-shard-merge-pessimistic
- Shard Merge(乐观):https://docs.pingcap.com/zh/tidb-data-migration/v5.3/feature-shard-merge-optimistic
- tiflow DM 源码目录:https://github.com/pingcap/tiflow/tree/master/dm